
Platforma SAP HANA stała się przyszłościową platformą dla rozwoju innowacji SAP. Łączy ona różne metody przetwarzania danych: transakcyjne, analityczne oraz funkcjonalne, wspierające logikę aplikacji, bezpośrednio w pamięci podręcznej. Taka architektura pozwala na realizację wymagających procesów biznesowych w czasie rzeczywistym, jednocześnie wspierając przetwarzanie OLAP i OLTP dla struktur danych. Stanowi najszybciej rozwijany produkt w historii SAP w znaczący sposób wpływający na kierunki rozwoju aplikacji. Aby uruchomić ten nowy cyfrowy rdzeń dla systemów SAP, wymagana jest nowoczesna infrastruktura IT własna lub dostawcy. Działy IT stają przed wyzwaniem konsolidacji zasobów wymaganych do utrzymania tradycyjnych systemów SAP ERP i SAP Business Warehouse (SAP BW), przy jednoczesnym zabezpieczeniu inwestycji przed ewentualną migracją do S/4HANA.
Uruchomienie nowych funkcjonalności dostarczonych wraz platformą HANA w wersji 2.0 może znacznie wpłynąć ma kierunki rozwoju infrastruktury, jak również na planowanie wykorzystanie dostępnych zasobów. Główne zmiany wprowadzone przez producenta oprogramowania polegają na zwiększeniu bezpieczeństwa danych, elastyczności oraz obniżeniu kosztów przechowywania w kontekście TCO.
Nie do przecenienia jest również równoległy rozwój wbudowanej architektury serwera aplikacji SAP HANA eXtended Application Services (XS), klasycznych i zaawansowanych modeli danych, funkcjonalności w obszarze „tenantów” czy narzędzi programistycznych i administracyjnych jak: SAP HANA studio czy HANA kokpit.
Redukcja TCO
Podczas planowania rozwoju istniejącej infrastruktury, jak również nowego wdrożenia lub migracji aktualnie posiadanych systemów na platformę HANA należy zastanowić się nad zarządzaniem kosztami TCO czy licencji. Nowe funkcjonalności dotyczące przechowywania danych pozwolą zmierzyć się z poniższymi wyzwaniami:
- Rozrost wolumenu danych wymusza rozbudowę systemu SAP HANA, doprowadzając do osiągnięcia limitów platformy;
- Wysoki koszt licencji na in-memory dla rozwiązań non-SAP, a korzystających z platformy SAP HANA;
- Rozrost wolumenu danych wpływa na czas wykonywania zapytań oraz wydajność całej platformy HANA.
Zmniejszając liczbę danych, które muszą być przechowywane w drogiej pamięci DRAM, można znacznie zredukować koszt infrastruktury wymaganej do utrzymania tych danych, jedocześnie utrzymując stały dostęp do nich z zadawalającą wydajnością.
Wraz z wprowadzeniem rozwiązania SAP HANA Data Tiering SAP udostępnił możliwość rozmieszczania danych w oparciu o ich wartość oraz czas dostępu. W takiej konfiguracji w pamięci operacyjnej przechowywane są dane najważniejsze, czyli te wymagające natychmiastowego dostępu, natomiast dane mniej istotne zostają przeniesione na nośnik zapewniający najlepszy stosunek kosztów do wydajności. Nowe funkcjonalności w tym obszarze zostały przez producenta określone terminami z przypisanymi do nich temperaturami danych: Hot Data Tiering, Warm Data Tiering oraz Clold Data Tiering.
SAP HANA Data Tiering
Hot Data Tiering
Wszystkie aplikacje mają te same możliwości przechowywania w pamięci. Dla danych o znaczeniu krytycznym, które wymagają dostępu w czasie rzeczywistym. Pamięć nieulotna (NVM), znana również jako pamięć trwała SAP HANA (PMEM), zapewnia dodatkową pojemność w stosunku do wykorzystanej pamięci podręcznej operacyjnej serwera. PMEM oferuje niższy całkowity koszt posiadania i krótszy czas uruchamiania bazy danych po zamknięciu niż DRAM, ale jej nie zastępuje, ponieważ DRAM jest nadal wymagany w systemach SAP HANA.
Warm Data Tiering
Gdy zestaw danych i dostęp do niego staje się mniej krytyczny, to natywnymi mechanizmami SAP BW on SAP HANA oraz SAP BW/4 HANA można „ochłodzić” temperaturę danych i przenieść je do rozwiązania dyskowego zapewniającego wydajność podobną do wydajności, gdy dane utrzymane są w pamięci DRAM. Narzędzie do modelownia Data Tiering Optimization (DTO) zarządza klasyfikacją oraz relokacją danych między SAP HANA a Native Storage Extension (nową funkcjonalnością wprowadzoną wraz z wersją SAP HANA 2.0 SP4). NSE jest dyskowym rozszerzeniem tabel przestrzeni dla tabel kolumnowych w SAP HANA. Zamiast wczytywać podczas uzyskiwania dostępu do danych całą kolumnę z tabeli, do pamięci podręcznej bufora są ładowane tylko potrzebne strony.
Dla natywnych aplikacji SAP HANA funkcję przechowywania mniej istotnych danych oferuje rozszerzenie Dynamic Tiering. Jest to funkcjonalność łatwa to zaimplementowania i zarządzania, ale nie obsługuje niektórych funkcji SAP HANA, takich jak funkcje geoprzestrzenne. W tym rozwiązaniu narzędzie Data Lifecycle Managment (DLM) ułatwia tworzenie warstw danych, umożliwiając oparte na regułach przenoszenie danych mniej istotnych.
Dla rozwiązań Business Suite on HANA oraz S/4HANA został zaimplementowany mechanizm zwany Data Aging, określający wartość danych na podstawie atrybutów. Mechanizm włączający Paged Attributes obecnie może być uruchomiony tylko na wybranych obiektach. Okresowe przebiegi zadania weryfikują informacje o przedawnionych obiektach, zrzucając je na dysk. W takiej konfiguracji tabele podzielone są na partycje z „gorącymi” danymi bieżącymi oraz „ciepłymi” danymi historycznymi.
Cold Data Tiering
Tak jak wszystkie dane w warstwie „gorącej” i „ciepłej” znajdują się w bazie danych SAP HANA, tak w warstwie „zimnej” dane znajdują się w systemach zewnętrznych, takich jak SAP IQ, SAP HANA Vora lub Hadoop. Narzędzie DTO pozwala sklasyfikować i przenieść dane o najmniejszej temperaturze do rozwiązania zewnętrznego. Dla pakietu Business Suite on HANA oraz S/4HANA podobną funkcję pełni narzędzie SAP Information Lifecycle Management (ILM) pozwalające określić atrybuty na obiektach, na podstawie których dane przenoszone są do zewnętrznego rozwiązania. Oba mechanizmy zapewniają dostęp do przeniesionych danych.
Powyższe mechanizmy powinny od samego początku projektowania stać się elementem strategii migracji oraz nowych wdrożeń. Ich wykorzystanie może znacznie zredukować koszty utrzymania infrastruktury IT.
Inną dostępną opcją redukującą koszt utrzymania platformy sprzętowej wyposażonej w dużą ilość pamięci podręcznej jest zastosowanie rozwiązań serwerowych z opcją Intel Optane. Ta technologia pozwala wykorzystać wolniejsze kości pamięci wbudowane w moduły DIMM. Pamięć PMEM (Persistent Memeory) to nowatorska technologia pamięci, która w unikalny sposób łączy dużą pojemność i trwałość danych z przystępną ceną. Może ona pomóc firmom podnieść poziom innowacyjności dzięki zwiększonej pojemności oraz nowoczesnym trybom pamięci, obniżyć ogólny całkowity koszt posiadania, maksymalizując przy tym gęstość maszyn wirtualnych, i poprawić poziom bezpieczeństwa pamięci za pomocą automatycznego szyfrowania sprzętowego.
Moduły PMEM używają tej samej magistrali, identycznych kanałów i funkcjonują jako zamiennik DRAM. Nie są one tak szybkie jak moduły pamięci DRAM. Jednak biorąc pod uwagę stosunek ceny do pojemności oraz opcję zwiększenia pojemności ponad możliwości oferowane przez pamięć DRAM, TCO jest znacznie niższy niż w przypadku pamięci DRAM. Dodatkową zaletą rozwiązania jest zachowanie danych w pamięci PMEM podczas restartu serwera. Nie ma konieczności ponownego ładowania dużych wolumenów danych podczas startu systemu, tym samym redukuje się czas jego niedostępności.
Bezpieczeństwo danych
Wraz z rozwojem platformy SAP HANA producent dostarczył nowe możliwości replikacji danych do systemów zapasowych. Zastosowanie mechanizmu nie tylko zwiększa bezpieczeństwo danych, ale również pozwala zoptymalizować sposób dostępu do nich, np. na potrzeby analityczne. Dane są w trybie rzeczywistym replikowane do drugiego zapasowego systemu HANA pracującego w trybie standby. Wersja systemu SAP HANA (2.0SP3) zapewnia dodatkowo mechanizm działania węzła standby w trybie tylko do odczytu. Funkcjonalność ta może być wykorzystana do raportowania przez podłączenie źródła danych z węzła standby, odciążając węzeł podstawowy. Tryb tylko do odczytu na węźle blokuje możliwość jakiejkolwiek manipulacji tymi danymi. Dane mogą być stale wstępnie załadowane do pamięci systemu pomocniczego, aby zminimalizować docelowy czas przywracania (RTO).
W wersji SAP HANA 2.0 SP4 producent oprogramowania wprowadził możliwość replikacji systemu do większej liczby systemów pomocniczych. Funkcjonalność może być wykorzystana w projektowaniu procedury DRC (zapasowe centrum danych), ale również do zniwelowania wpływu sieci rozległych na dostęp do danych w różnych lokalizacjach geograficznych. Rozwiązanie to pozwala na umieszczenie platformy HANA w dowolnej lokalizacji i replikowanie do niej danych z systemu produkcyjnego. Na tak zreplikowanych danych mogą być wykonywane lokalnie wszelkie operacje analitycznie niewymagające zmiany danych źródłowych. Dane mogą być modyfikowane tylko w systemie centralnym.
Tryby replikacji SAP HANA
- Synchroniczna na dysku (tryb = sync): transakcja jest zatwierdzana po zapisaniu wpisów dziennika w systemie podstawowym i pomocniczym;
- Synchroniczna w pamięci (tryb = syncmem): transakcja jest zatwierdzana po otrzymaniu dzienników przez system pomocniczy, ale przed zapisaniem ich na dyskach. Ten rodzaj synchronizacji jest rekomendowany w scenariuszu, gdy oba węzły umieszczone są w jednej sieci, charakteryzującej się dużą przepustowością i niskimi czasami dostępu;
- Asynchroniczny (mode = async): transakcja jest zatwierdzana po wysłaniu wpisów dziennika bez żadnej odpowiedzi z systemu pomocniczego;
- Pełna synchronizacja: pełna synchronizacja jest obsługiwana przez SAP, ale nie można jej skonfigurować za pomocą oprogramowania wysokiej dostępności.
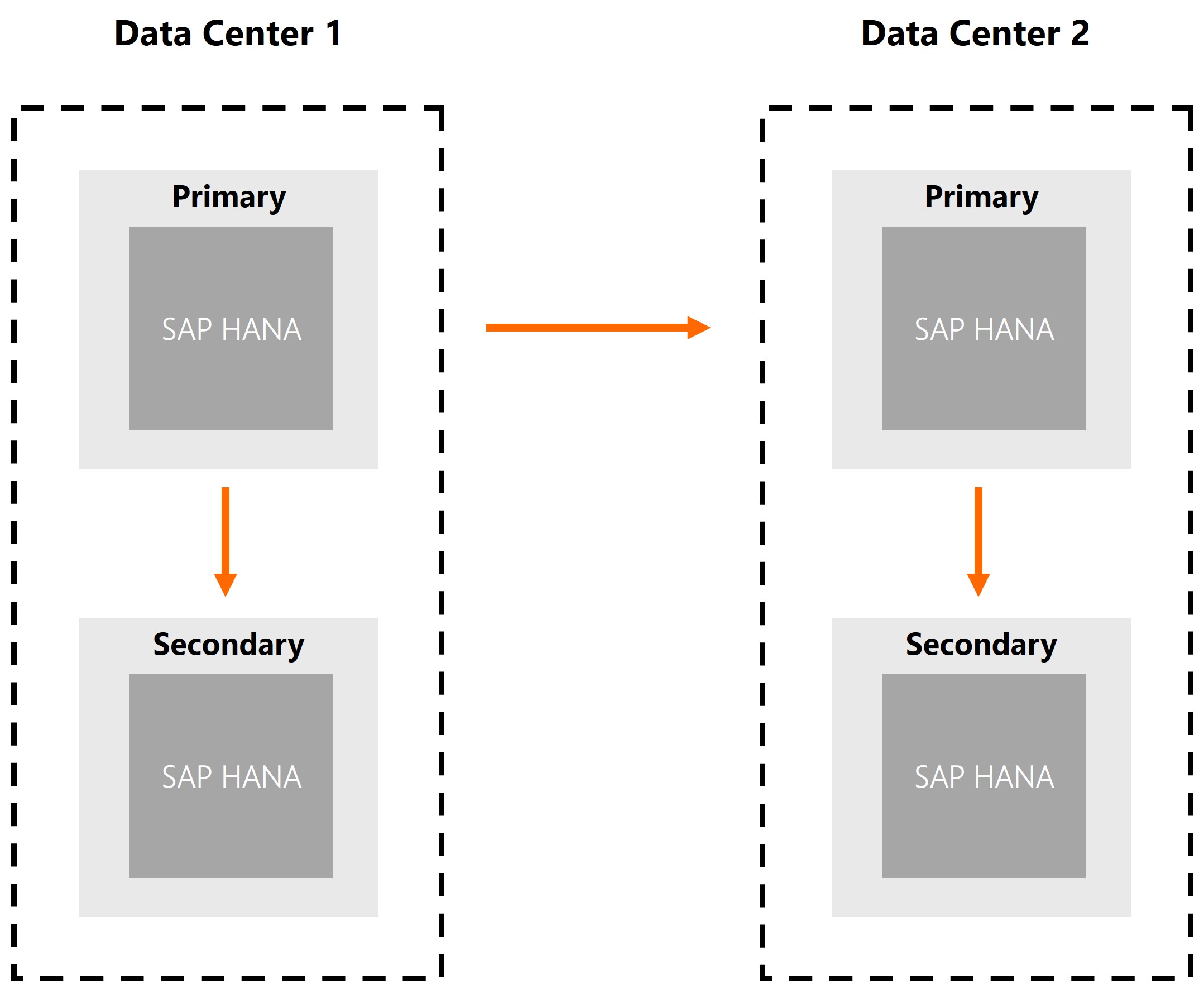
Replikacja systemu do systemów pomocniczych w SAP HANA 2.0
Anonimizacja i maskowanie danych
Nowa wersja platformy umożliwia wykorzystanie danych do analiz i scenariuszy uczenia maszynowego w kontekście RODO i innych przepisów chroniących prywatność. Dzięki algorytmom k-anonimowości i prywatności różnicowej dane są przesyłane w taki sposób, że wynik pozostaje statystycznie ważny, ale nie można go już powiązać z osobami. Dodatkowo można dodać niestandardową definicję widoków anonimizacji, uzyskać dostęp do widoków raportowania i skorzystać z integracji frameworkiem autoryzacji.
Natywne dynamiczne maskowanie danych SAP HANA jest dostępne w SAP HANA i SAP HANA Cloud. Ta funkcja chroni dane na poziomie wiersza z maskowaniem danych w tabelach i widokach. Dane nie są replikowane, ale maskowane w locie, jeśli mają do nich dostęp nieupoważnieni użytkownicy. Maskowanie w SAP HANA jest wysoce konfigurowalne i można je dostosować do wymagań.
Natywny serwer aplikacji
Chociaż SAP S/4HANA i SAP BW/4HANA obsługiwane przez serwer aplikacji NetWeaver, to SAP HANA ma również własny wbudowany, „natywny” serwer aplikacji. Pierwsza wersja była oparta na silniku JavaScript SpiderMonkey. Miał on minimalny rozmiar i nazywał się SAP HANA eXtended Application Services, w skrócie XS. Ponieważ architektura ta miała swoje ograniczenia, wraz z nową wersją dodano zupełnie nowy serwer aplikacyjny, tym razem oparty na open-source Cloud Foundry. Lokalna dystrybucja Cloud Foundry została zintegrowana z platformą in-memory i przemianowana na XS Advanced (XSA), przy czym oryginalna implementacja XS została teraz oznaczona jako „klasyczna”.
Funkcjonalności serwera aplikacji programista wykorzystuje w aplikacji do projektowania zwanej SAP Web IDE.
SAP HANA Cockpit 2.0
W nowej wersji platformy SAP HANA producent rekomenduje wykorzystanie nowej wersji scentralizowanego kokpitu opartego na ekspresowej wersji SAP HANA, z własną zaawansowaną infrastrukturą serwera aplikacji XS oraz z wszechstronnymi i łatwymi do użycia narzędziami do zarządzania systemami.
Dzięki nowemu kokpitowi możemy zarządzać zarówno całymi krajobrazami systemów SAP HANA, jak i pojedynczymi systemami. Integracja systemów HANA z SAP HANA Cockpit 2.0 nie wyklucza możliwości dalszego korzystania z dobrze znanego rozwiązania opartego na środowisku Eclipse – HANA Studio.
Jeszcze więcej nowości
Powyższa lista to najmniejszy wybór nowości w SAP HANA 2.0. Platforma umożliwia organizacjom przyjęcie reguł i standardów bezpieczeństwa oraz zapewnia narzędzia niezbędne do wprowadzania innowacji w dzisiejszym środowisku biznesowym. Organizacje mogą wdrażać wymagające rozwiązania, które posłużą do zdobycia przewagi informacyjnej. Łatwość konfiguracji, zarządzania i monitorowania zabezpieczeniami pozwala wyprzedzić konkurencję, jednocześnie spełniając wymagania dotyczące prywatności, reguł prawnych oraz zgodności. Producent nieustająco wspiera swoich klientów w maksymalizacji korzyści i ochronie ich inwestycji, wyznaczając drogę w przyszłość.
W kolejnych odsłonach planowane są nie tylko poprawa stabilności i jakości, ale również wprowadzenie innowacji redukujących całkowity koszt posiadania i zwiększających użyteczność, ale także ulepszone możliwości uczenia maszynowego dzięki nowym algorytmom PAL, które są wspierane przez Python 3. Dostępne będą dalsze aktualizacje do natywnego rozszerzenia pamięci masowej, które uzupełniają możliwości SAP HANA w zakresie Big Data. W najbliższych latach platforma SAP HANA będzie integrowana z przyszłymi produktami SAP, stanowiącymi platformę inteligentnego przedsiębiorstwa.