
Graylog to scentralizowane rozwiązanie do zarządzania logami, zbudowane według otwartych standardów opensource. Rozwijane od 2009 r. narzędzie jest wykorzystywane do przechwytywania, przechowywania i analizy logów w czasie rzeczywistym. Służy do gromadzenia i analizy logów z różnych źródeł: systemów operacyjnych, serwerów aplikacji, firewalli sprzętowych i programowych. Może być stosowane do monitorowania stron internetowych, aplikacji webowych i wielu innych obszarów infrastruktury informatycznej.
Tym, co odróżnia Graylog od centralnego serwera Syslog, jest wykorzystanie bazy danych Elasticsearch do przechowywania oraz indeksowania dokumentów. Baza ta umożliwia przeszukiwanie milionów rekordów z logami w czasie poniżej sekundy. To imponujący wynik w porównaniu ze zwykłym przeszukiwaniem logów poprzez linuxowy grep czy wykorzystanie ctrl+F w notepadzie.
Identyfikacja logów
W czasie odbierania wiadomości Graylog dokonuje jej rozdzielenia na mniejsze pola. Poniżej przedstawiamy przykładowy podział logów z serwera Nginx.
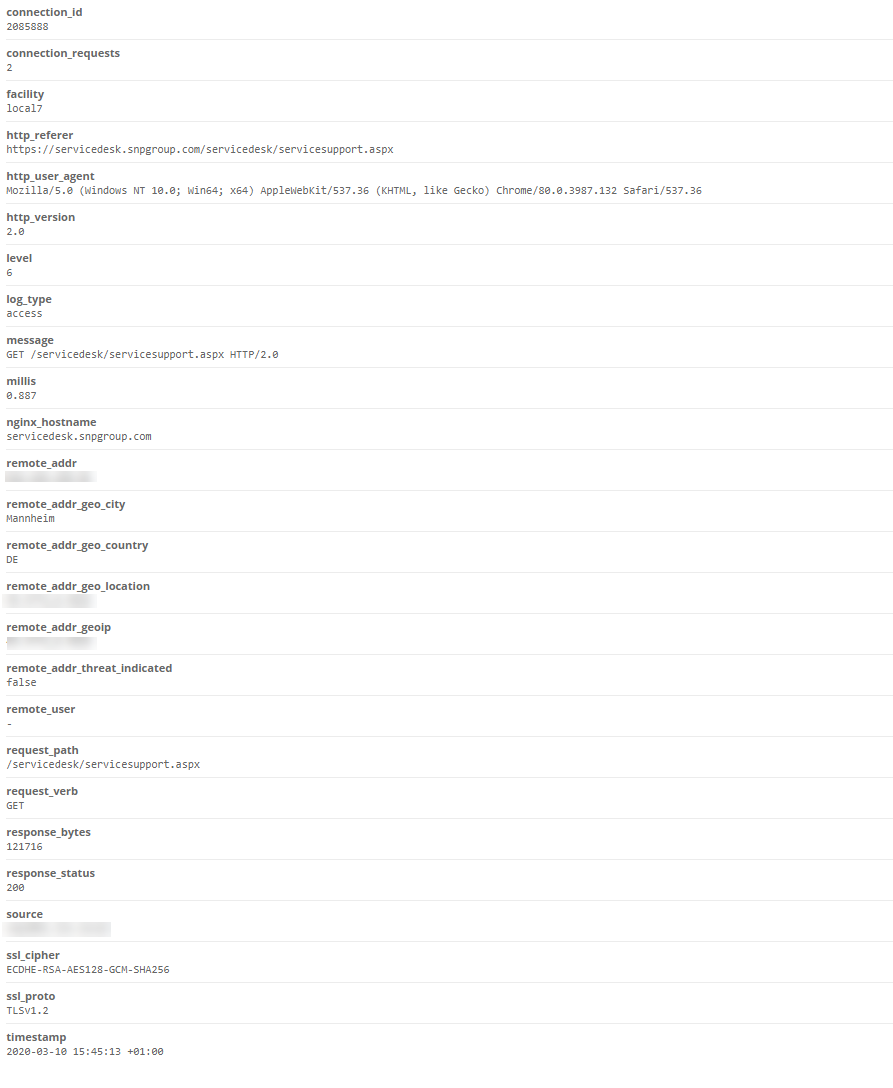
Przykładowy podział logów z serwera Nginx
Dzięki podziałowi łatwo można wyszukać wszystkie logi wygenerowane przez pojedynczy adres IP, zakończone kodem 200, bez pisania zaawansowanych wyrażeń regularnych.
Graylog jest zintegrowany z takimi usługami jak:
- AlienVault Open Threat Exchange (OTX),
- Spamhaus DROP/EDROP lists,
- ch Ransomware Tracker blocklists.
Integracja pozwala każdy adres IP i każdą domenę oceniać pod względem ich reputacji i dodać odpowiednią informację w logu, jeśli reputacja danego adresu IP/domeny jest niska. W ten sposób uzyskamy informację o ruchu przychodzącym z mało wiarygodnych adresów.
Możemy także zintegrować Grayloga z bazą GeoIP2 i dopisywać koordynaty geograficzne do każdego adresu IP, jaki pojawi się nam w logach, a także wyciągać dane z bazy WHOIS i dopisywać te informacje do każdego adresu IP. Taka identyfikacja może być przydatna nie tylko w administracji i monitoringu infrastruktury IT. W wielu firmach takie dane o logowaniu są na wagę złota dla działów marketingu, sprzedaży i bezpieczeństwa.
Jednakże samo przechowywanie logów w centralnym repozytorium, bez ich praktycznego wykorzystywania na co dzień, nie ma dla przedsiębiorstwa żadnej wartości. Dobre narzędzie do analizy logów musi udostępniać mechanizmy pozwalające na łatwy dostęp do statystyk i trendów, a także alarmujące o pojawiających się nieprawidłowościach.
Przydatne dashboardy
Pierwszą czynnością administratora, który chce w pełni korzystać z danych z logów, powinno być przygotowanie w Graylogu ekranu kontrolnego (dashboardu), który pozwoli na przejrzystą prezentację informacji oraz zaawansowanych statystyk. Dobrze przygotowana wizualizacja danych zgromadzonych w logach pozwali nam szybko i łatwo ocenić, co się dzieje z naszymi systemami.
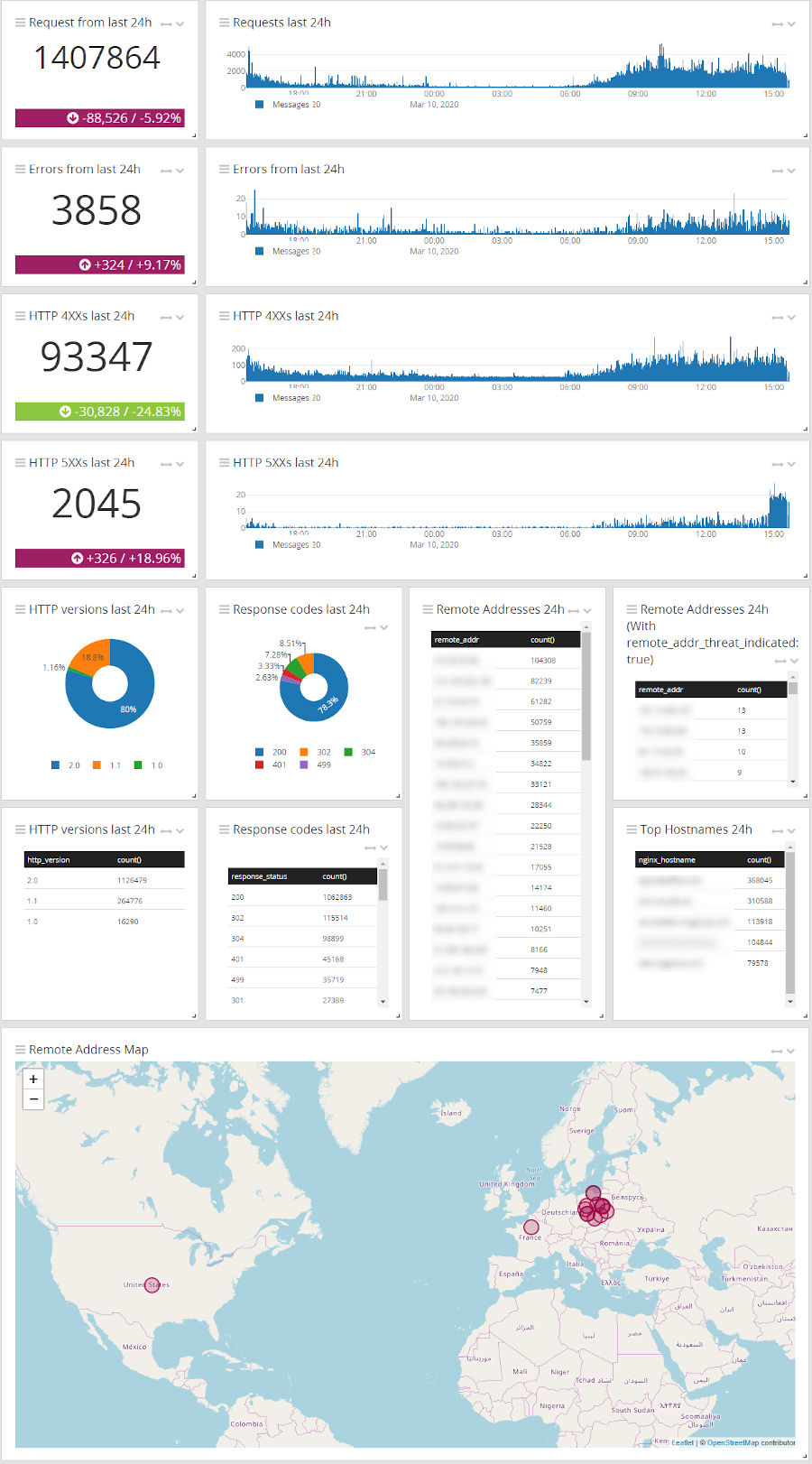
Przykładowy ekran kontrolny logów w Graylog
Dobrze zbudowany, spersonalizowany pod konkretne potrzeby dashboard w znacznym stopniu upraszcza codzienną pracę. Prezentacja na ekranie tylko najważniejszych danych w postaci czytelnych wykresów, diagramów czy alertów na pierwszy rzut oka pozwalają rozeznać się w sytuacji. Na przykład dedykowany ekran dla zespołu HelpDesk może zawierać istotne z jego punktu widzenia dane:
- kto w ostatnim czasie niepomyślnie się logował,
- kto ostatnio zablokował swoje konto w domenie,
- jaka grupa ostatnio zmieniła swoich członków.
Wydobycie powyższych informacji bezpośrednio z logów w sposób manualny byłoby zadaniem karkołomnym i czasochłonnym, gdyż wymagałoby przeszukiwania milionów logów, by znaleźć jeden istotny rekord.
Warto też podkreślić, że wysyłając logi do Graylog, tworzymy ich kopię w dodatkowym i niezależnym miejscu. Nie musimy się już obawiać, że ktoś je nam skasuje z systemu źródłowego lub utracimy je wskutek awarii.
Jak już zostało to wspomniane na wstępie, za przechowanie danych dla Grayloga odpowiada popularne i znane rozwiązanie o nazwie Elasticsearch. Ta wyspecjalizowana baza danych dostarcza bardzo wiele możliwości dostępu do danych w różnych konfiguracjach poprzez zintegrowane z nią aplikacje (integracja poprzez API). Jedną z bardziej użytecznych jest Grafana. To kolejne opensourcowe narzędzie jest szeroko wykorzystywane przez tysiące firm jako pomoc w monitorowaniu infrastruktury IT i aplikacji (ale nie tylko, jest też pomocne np. w zarządzaniu infrastrukturą przemysłową, turystyce, marketingu i wielu innych branżach). Grafana pozwala wyszukiwać, wizualizować i ostrzegać, a także dogłębnie eksplorować i rozumieć dane, bez względu na to, gdzie są przechowywane.
Klastry, formaty danych, uprawnienia
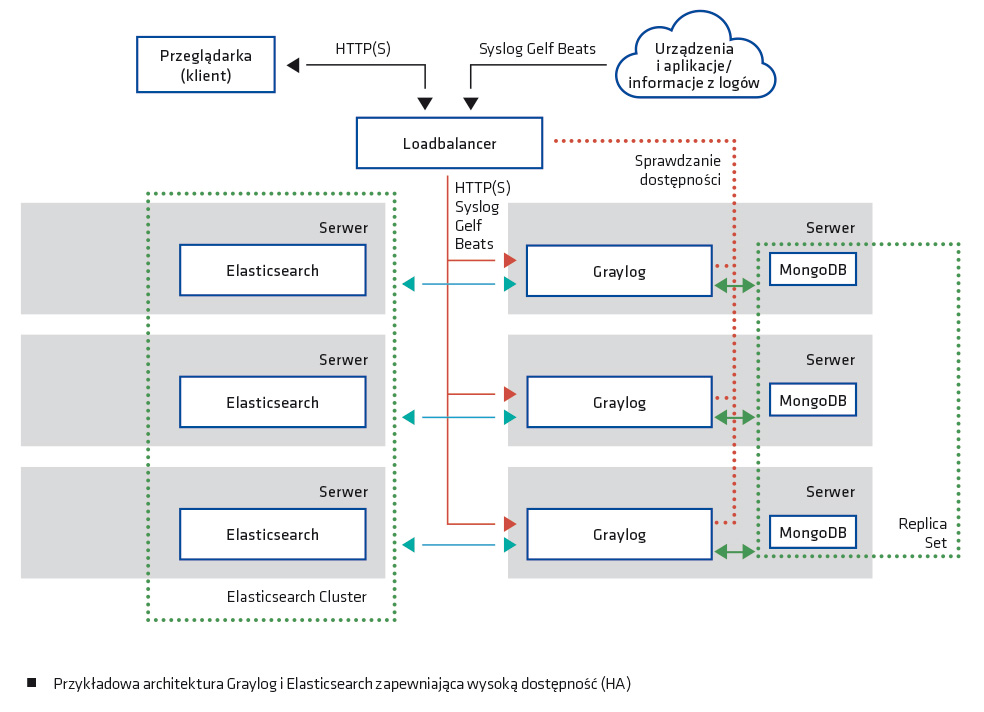
Wróćmy jednak do Elasticsearch i Grayloga. Jedną z dużych zalet tych rozwiązań jest możliwość prostego klastrowania. Dzięki temu można równomierne rozkładać obciążenie i uzyskać wysoką dostępność aplikacji oraz najważniejszych logów poprzez składowanie ich na kilku węzłach Elasticsearch. Wielkość zbioru danych przechowanych przez Elasticsearch w pełni zależy od nas, gdyż mamy pełną kontrolę nad ich retencją. Do dyspozycji są trzy kryteria usuwania danych: wielkościowe, ilościowe i czasowe. Możliwe zatem jest usuwanie zgromadzonych danych, do wyboru: po wielkości zbioru (usuwa najstarsze po przekroczeniu zadanej wielkości), liczbie rekordów lub wieku (starsze niż).
Graylog posiada bardzo rozbudowane oraz dobrze opisane API. Efektem jego wykorzystania może być np. informacja o liczbie błędów aplikacji, które pojawiły się w ciągu ostatnich 5 minut, zamieszczona w centralnym systemie monitującym (np. Zabbix). Dzięki temu monitoring systemów obsługiwany jest w jednym systemie.
W narzędziu dostępny jest również rozbudowany system powiadamiana (alertowania). Alerty można wysyłać w formie powiadomienia mailowego, wiadomości na Teams/Slack lub wysyłać je do systemu agregującego alerty, jakim jest Alerta. Zdarzenia można agregować z różnych źródeł, jak choćby z Active Directory i firewall, w celu np. wykrycia próby skanowania portów w sieci lokalnej lub próby nieudanego logowania na nasze systemy.
Graylog obsługuje sporo formatów odbieranych danych:
- Syslog (TCP, UDP, AMQP, Kafka),
- GELF (TCP, UDP, AMQP, Kafka, HTTP),
- AWS – AWS Logs, FlowLogs, CloudTrail,
- Beats/Logstash,
- CEF (TCP, UDP, AMQP, Kafka),
- JSON Path from HTTP API,
- Netflow (UDP),
- Plain/Raw Text (TCP, UDP, AMQP, Kafka).
Jeżeli chodzi o metody przesyłania danych z systemów źródłowych do Graylog, to dostępne są:
- wysyłanie logów poprzez Syslog,
- wysyłanie logów w formacie GELF poprzez http API,
- wykorzystanie rozwiązań zbierających logi i transportujących bezpośrednio do Graylog:
- NXLog,
- Filebeat,
- Audibeat,
- Winlogbeat.
Powyższe metody umożliwiają czytanie plików płaskich, przekazywanie logów z Windows Event Log lub integrację własnych aplikacji z Graylog, aby wysyłały logi bezpośrednio do niego.
Jeśli Graylog ma pełnić rolę centralnego systemem do gromadzenia i zarządzania logami, ważnym aspektem jego działania jest system nadawania uprawnień. Także i w tym zakresie rozwiązanie posiada bardzo rozbudowane możliwości. Można go zintegrować z AD/LDAP, tworzyć odpowiednie role i nadawać szczegółowe uprawnienia. Role możemy połączyć z grupami użytkowników w AD/LDAP, tak by w jednym miejscu zarządzać nadawaniem uprawnień. Same uprawnienia możemy ograniczać do pojedynczego widoku logów (np. tylko logi z danej grupy systemów albo tylko logi związane z naszym AD), widoku dashboardów czy też ich edycji.
Graylog Marketplace
Wokół Graylog utworzyła się rozbudowana społeczność programistów i użytkowników. Wiele osób publikuje opracowane przez siebie rozwiązania na oficjalnym Graylog Marketplace (marketplace.graylog.org), gdzie można znaleźć i pobrać:
- gotowe dashboardy,
- gotowe filtry danych i ekstraktory (dzielenie wiadomości na pola),
- rozszerzenia funkcjonalności (np. integracje ze Slackiem/Teams).
Niezależnie od wielkości organizacji, wdrożonych systemów, czy też liczby wykorzystywanych aplikacji, możemy w Graylog gromadzić wszystkie logi. Gromadzić i odpowiednio wizualizowań, a tym samym pomóc administratorom w codziennej pracy, a menedżerom dać więcej przystępnie zaprezentowanej wiedzy o tym, co aktualnie dzieje się w ich środowisku. Należy jednak pamiętać, że mimo iż Graylog posiada funkcjonalności Threat Inteligence, nie jest to w pełni zautomatyzowany system SIEM (Security Information and Event Management).
Szerokie możliwości integracji z innymi rozwiązaniami, a także duża elastyczność to największe zalety Graylog. Jako narzędzie do przechowywania i agregowania logów sprawdza się doskonale.