
The ABAP programming language is the basis of the SAP system. SAP NetWeaver Application Server ABAP (AS ABAP) is the main application server for solutions, such as SAP Business Suite, SAP BW and other products offered by SAP. At the same time, the key technology innovations, such as cloud, mobile or in-memory solutions, provide SAP customers and partners with the ability to respond to new business needs, and offer a chance to stand out among the competition through the use of superior technology.
This article presents the essential elements of application programming for SAP HANA, which can improve the speed and computing power of developed solutions. In addition, we will present some examples of new possibilities that SAP HANA offers developers. But before we get into details, we would like to point out two major issues. The first of these is how to use the ABAP programming language and SQL query language in the new environment offered by SAP HANA. The second issue is the development of solutions in the SAP landscape.
ABAP and SQL in SAP HANA environment
SAP HANA is compliant with the ACID (Atomicity Consistency Isolation Durability) model which applies to databases. ACID is a set of properties that guarantee that transactions are processed correctly in databases. The acronym stands for:
- Atomicity – meaning that each transaction is either executed in whole or is not executed at all; for example, if a transaction consists of a bank transfer (where one bank account is debited and another one is credited with the same amount), then the situation where one account is debited and the amount on the target account is unchanged cannot occur: the bank transfer is either executed in whole or not executed at all;
- Consistency – the transaction consistency means that the system remains consistent after the transaction is executed, i.e. no integrity rules are violated;
- Isolation – isolation of a transaction means that when two transactions are executed concurrently, they usually (depending on the isolation level) do not see changes made by the other one. The isolation level in databases is usually configurable and determines what anomalies can be expected when executing transactions.
- Durability means that once a transaction has been committed, it will remain so, even in the event of power loss, crashes, or errors. In a relational database, for instance, once a group of SQL statements execute, the results need to be stored permanently (even if the database crashes immediately thereafter). To defend against power loss, transactions (or their effects) must be recorded in a non-volatile memory.
From a technical point of view, SAP HANA is similar to any other database a developer happened to be working with. It uses SQL and MDX, has JDBC and ODBC libraries, stores data in tables, in columns and rows, and requires administration and backup. However, there are several key differences and some new capabilities available that should be taken into account when building applications for systems with SAP HANA as a database. First of all, one should say goodbye to several fundamental principles that applied to previous system versions in order to use all new possibilities offered by SAP HANA.
Technically, SAP HANA is compliant with standard interfaces of every database. Therefore, to start using it, you could simply use existing applications, change ODBC or JDBC interface settings, a then run them in the same way as previously, but with SAP HANA as a new database layer. However, in such a scenario, the problem is that SAP HANA offers new capabilities that are missing in other databases. Its advantages include, for example, better basic technical capabilities of the database.
In addition, SAP HANA goes far beyond traditional databases, offering a complete application and development platform, and provides better capabilities in areas such as searching, predictive analysis, etc. Therefore, building applications while taking into account these specific advantages will allow the developer to create the most innovative solutions.
Without limitations
A few years ago, in a traditional architecture based on disk spaces, writing a complex algorithm that simultaneously retrieves raw data from 200 large unique tables (of 100 million rows) and establishes connections on the fly was considered stupid and even impossible.
And what if it was not stupid or impossible? What if the algorithm is of great business importance for end users? What if there was no penalty for writing this algorithm? What if it was possible to obtain the results of such calculations within a few milliseconds, rather than several hours? What if the developer had a supercomputer available to calculate such an algorithm whenever needed? What if in addition to the execution of these operations in a database it was possible to move all other application and presentation layers directly to the database to provide a simple, uncomplicated platform on which to run the entire application?
Such an approach is a kind of philosophical change required for the transition from limited programming to the new world of SAP HANA. In SAP HANA, old database constraints and limited computing power become largely irrelevant. The boundary where the database ends and the application server begins is also strongly questioned.
Abstraction
In the SAP world (and especially in the ABAP world), developers learn to completely separate their applications from the database and treat it as a ‘black box’. The database is only used to store data, and the ABAP engine is responsible for the whole application logic and generating of SQL queries. ABAP developers often have no idea which database their application will use, therefore they must use optimal methods, but without indicating a specific database.
Unfortunately, to maintain compatibility of created solutions, they often have to resign from capabilities offered by individual databases. This extreme separation of application logic and data storage has been one of the cornerstones of ABAP application development for the past 20 years, mainly because it was the most effective SAP strategy to achieve a compromise between the broad support for multiple databases and performance of individual applications.
In contrast to this approach, in SAP HANA you know exactly with which database the created application will work. We also know that SAP HANA has been optimized to meet the needs of a given application. Consequently, the ABAP engine can use not only the speed of the processor memory, but it can also take advantage of all the capabilities offered by SAP HANA for calculations and business functions.
With SAP HANA, many performance-related tasks are actually executed at the database level. Thus, SAP HANA allows developers to penetrate deeply into the data model. In addition, its features allow them to perform intensive operations at the data level, and not in the application itself, as it was so far in disk-based databases.
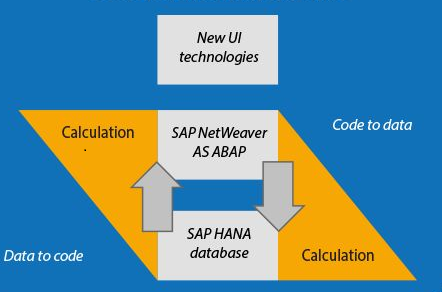
In the old programming paradigm, developers while designing an application, writing its logic or processing data, often left the database completely intact. Such an application retrieved the necessary data from the database, processed and transformed it, and then started the calculations and algorithms, and finally presented the final results to the user.
In SAP HANA, the process is reversed. The application is only responsible for the business logic. A called function is fully responsible for the retrieval of answers from the database. Data transformations, algorithm and calculations are executed within the database, and only their result is returned to the application.
Transferring all data-intensive operations to the database level and calling these operations as functions from the application level makes the whole architecture much more elegant and efficient. In fact, companies that decided to use SAP HANA notice the improvement in application performance by hundreds of thousands of times.
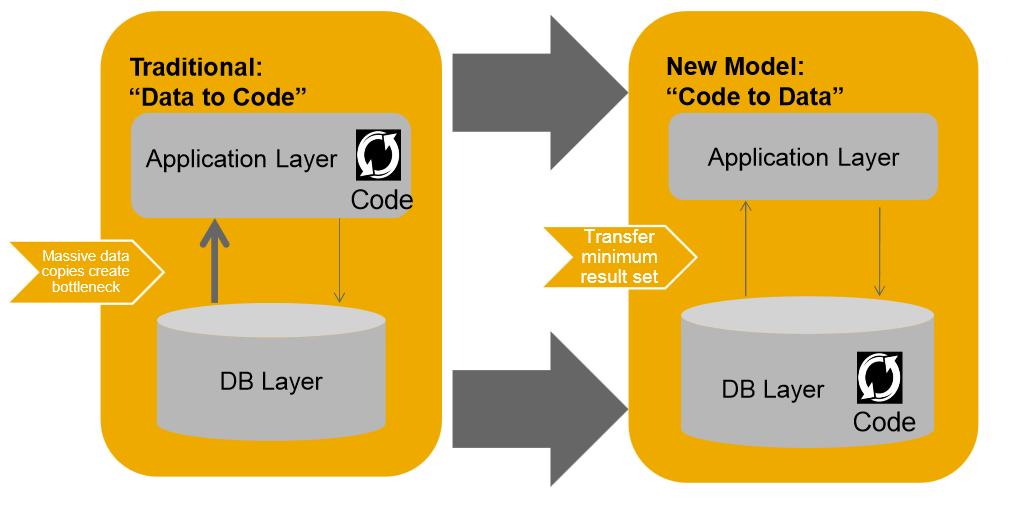
SQL script – traditional model vs. new model
The transition from data processing at the application level to data manipulation at the database level is necessary for the use of all SAP HANA capabilities. Certainly, when migrating to SAP HANA you can still use old applications and get a bit shorter response time, because another advantage of the SAP HANA database is that it resides in memory. When data-intensive operations are moved directly onto the SAP HANA database level, not only the architecture is simplified and application performance improved, but also a significant improvement in operation performance is noticeable.
ABAP programming for SAP HANA
As ABAP is the basic application programming language in the SAP Business Suite family, it plays an important role in migrating the existing customer’s database to SAP HANA. Therefore many people are interested in how they can use SAP HANA in SAP Business Suite and how they can use ABAP in order to take advantage of capabilities offered by SAP HANA. There are several different configurations where ABAP and SAP HANA can work together to create and use innovative features in SAP Business Suite.
Find discussed below, several scenarios that use the power of SAP HANA in new and existing SAP Business Suite applications. These scenarios range from very simple applications that do not require the system operation to be interrupted to speed up problematic transactions or reports to the launch of the entire SAP Business Suite system directly from SAP HANA as a primary database.
SAP HANA as an additional database
In this scenario, let’s assume that SAP HANA is installed as a secondary database, and not as a replacement for the existing one. Then, through replication, the data copy can be transferred from the original database to the SAP HANA system. ABAP applications can be accelerated because they will read the data from the copy of SAP HANA instead of the local database.
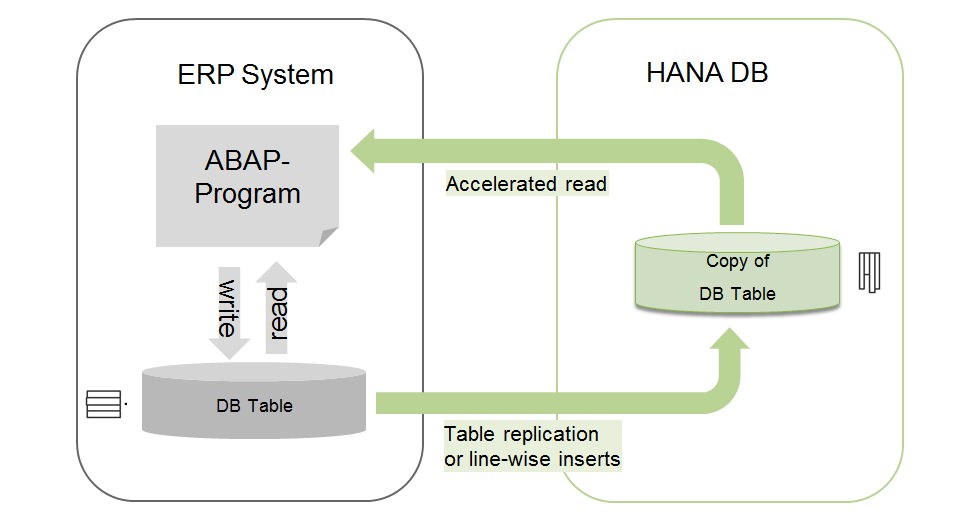
ABAP connection to external database via Open SQL
The simplest solution for executing SQL transactions from ABAP in the connected external database is the use of Open SQL queries that are well known to ABAP developers. By filling in additional parameters in CONNECTION (dbcon) syntax, you can force the Open SQL statement to be executed in the connected, alternative database.
For example, let’s take a simple SELECT statement and execute it on the SAP HANA database:
![]()
The advantage of this solution is its simplicity. Using one small addition to existing SQL commands you can redirect queries to SAP HANA. The drawback is that the table or view from which the data is retrieved must exist in ABAP Data Dictionary.
In this scenario it is not a big problem, as all data stored in the local ABAP database is replicated to SAP HANA. In this situation, local copies of data tables will always exist in ABAP Dictionary. Remember, however, that SAP HANA-specific extensions, such as Analytic Views and database procedures are inaccessible this way. It is also impossible to access any tables that exist only in SAP HANA.
ABAP connection to external database via Native SQL
In ABAP syntax, it is also possible to use Native SQL. In this scenario, the code includes database-specific elements of SQL syntax. This process allows access to tables and other database components that only exist in the main database. In addition, Native SQL includes the syntax which allows calling database procedures. The above example can be re-written in Native SQL as follows:

The disadvantage of using Native SQL through EXEC SQL command is that in such an approach the correctness of SQL queries is not checked. Any errors will not be detected until the query is executed, which can lead to ABAP runtime errors (so-called “short dumps") if handling of such exceptions is not implemented in the code. Because of this limitation, the solution testing is absolutely necessary when using Native SQL to ensure correct operation.
ABAP connection to external database via Native SQL – ADBC
The third scenario provides benefits of connecting Native SQL through EXEC SQL while eliminating some limitations. In this case, we are dealing with the concept of ADBC – ABAP Database Connectivity, which essentially consists of a series of standard ABAP classes (CL_SQL*). With ADBC class methods, it is possible to send database-specific SQL queries and process the results, as well as to establish and manage a database connection, and all this is covered in the code which simplifies a complex EXEC SQL syntax. Our sample query can be re-written as follows:
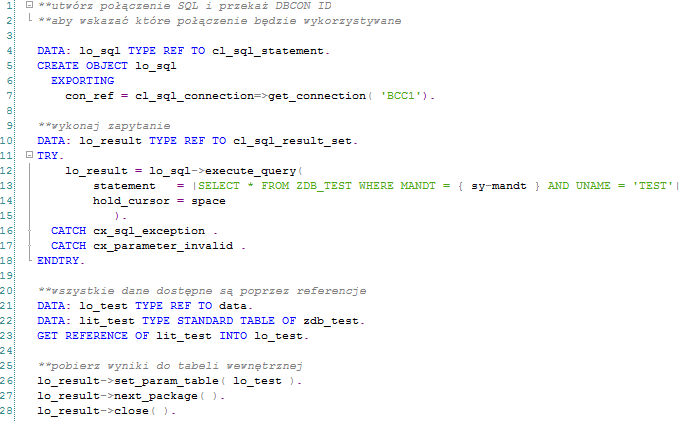
In this case, a single-step database access for each row is eliminated and replaced by the upload of the whole data package to our internal table. From the SAP HANA perspective, the most important is the fact that when using ADBC properties it is possible to access non-Data Dictionary elements of the database, including stored procedures in SAP HANA. Taking into account these advantages of ADBC over EXEC SQL, SAP recommends using ADBC classes every time.
The above example shows very simple SQL queries, but the real advantages of using SAP HANA as an external database can be noticed when executing more advanced queries (SELECT SUM … GROUP BY), accessing specific SAP HANA attributes or database procedures.
SAP HANA as a primary database
SAP HANA may of course be used as the primary database in each system based on the ABAP programming language. As part of the SAP Business Suite based on SAP HANA, ABAP-based applications (such as ERP) can be run from SAP HANA as the primary database management system. In this case, also ABAP had to be expanded to provide new tools and techniques, and to allow developers to directly access individual SAP HANA functions.
So far, we have presented how you can access an external database using Open SQL and Native SQL from ABAP. We also know that Open SQL is limited only to objects defined in ABAP Data Dictionary. In response to those limitations, a new approach was introduced in ABAP 7.4, called Data Dictionary Proxy Views. Proxy Views allow developers to create entries in ABAP Dictionary that are specific to SAP HANA views – Analytic, Attribute and Calculation views. Developers can use Proxy Views, thus improving the quality and ease of use of Open SQL for SAP HANA specific views. Such approach is especially useful if combined with ABAP types, such as Select-Options and Parameters.
Another innovation in ABAP 7.4 related to SAP HANA is Proxy Procedures. Proxy Procedures generate both ABAP interface and data types specific to stored procedures in SAP HANA. For that purpose, new ABAP syntax (CALL PROCEDURE) was introduced with which calling the procedure from SAP HANA is very similar to calling an ABAP function module.
Both Proxy Views and Proxy Procedures make use of Native SQL unnecessary for accessing database-specific functions. With both of these additions, developers have by far less work to develop a code which exploits the capabilities of SAP HANA. They also allow them to improve efficiency of data transfer between ABAP application server and SAP HANA.
Data processing closer to databases
Irrespective of whether SAP HANA is used as a primary or secondary database, developers must adopt different code development strategies, if they want to use all advantages of SAP HANA. ABAP developers usually avoid complex SQL queries and prefer data processing at the ABAP application server level.
This approach has served ABAP developers for many years. To retrieve data from foreign key dependent tables in ABAP we can write the following code using the inner join statement:

However, many developers would choose a different approach, in which data joining would be executed at the application server level through the use of internal tables.
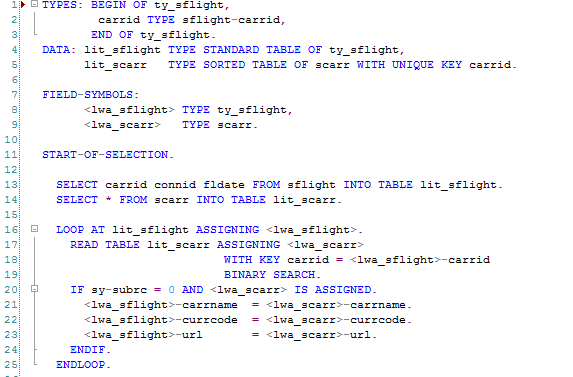
This approach may be beneficial, if the tables used in the query are buffered. The above examples show the available design patterns, and not technical aspects of these queries.
How will the developer’s approach change, if we add SAP HANA? In HANA, the developer should seek to transfer as many operations as possible to the database level. You may ask, why?
To answer this, note that SAP HANA is an in-memory database. Each developer will appreciate advantages of consolidating all data in fast memory, as opposed to storing data in a relatively slow disk space. If it was the only advantage of SAP HANA, it would be difficult to notice a huge difference compared to processing in ABAP. Finally, ABAP also offers full in-memory buffering of tables.
Other key points of the SAP HANA architecture besides in-memory processing are; data storage in columns and parallel processing. In the ABAP loop for an internal table, each table record must be processed sequentially, one record at a time, and the existing version of ABAP syntax is not designed for parallel processing. Instead, ABAP uses many server processes, running different user sessions in separate work processes.
In contrast to these limitations, SAP HANA may process data blocks in parallel in a single query. The fact that data is stored in memory additionally supports parallel processing through an easier and faster access to data by the processor. Parallel processing will not be useful at all, if the processor is idle most of the time waiting for access to the data.
Another important technical aspect is the column-oriented architecture of SAP HANA. When data is stored in a table in columns, all data for one column is stored in the memory. This is in contrast to storing data in rows where only one row at a time is loaded into the memory, like in the processing of ABAP internal tables.
Thus, for the above-mentioned join clause, the values for the column CARRID in each table can be read faster due to data deployment. Searching through unnecessary data in the memory is not as performance-intensive as executing the same operation on the disk (due to the need to wait for the platter rotation). Storing data in columns reduces the cost of carrying out works such as searching one or more columns, as well as optimizing compression procedures.
For these reasons, developers (especially ABAP developers) need to rethink the design patterns used. To take advantage of the maximum benefits offered by SAP HANA, they also have to move most of the operations performed so far in ABAP to the database level. This is due to greater use of SQL queries and more frequent interactions with the database. In this way, the database becomes another development tool with capabilities that should be fully utilized.
SAP HANA Extended Application Services (XS)
With SAP HANA SP5, SAP introduces new capabilities within SAP HANA Extended Application Services (also called XS or XS Engine). The concept of this solution is based on embedding a fully functional application server, Web server and development environment within SAP HANA. This is not just a piece of software installed on the same machine as SAP HANA, but a fully integrated new functionality of application services at the SAP HANA database level. This innovative architecture increases application performance and gives access to many specific features of SAP HANA.
Before the introduction of SAP HANA SP5, to build a simple website or a service that uses SAP HANA, it was necessary to use a different application server within the system landscape, e.g. through the use of SAP NetWeaver ABAP or Java connected to SAP HANA to transfer SQL queries to it. This mechanism is still possible, especially when extending existing applications with new SAP HANA functionalities. Such integration is easy to perform and carries a minimal risk of disruption.
However, when new SAP HANA-specific applications are built from scratch, it is worth considering the option of using SAP HANA XS. With this new architecture, it is possible to create and deploy completely independent applications within SAP HANA. This approach reduces development costs while providing high performance of solutions since the application itself and the program logic control are so close to the database.
SAP HANA Studio – new development environment
To support developers in creating applications and services directly in SAP HANA XS, SAP expanded SAP HANA Studio with all necessary tools. SAP HANA Studio is a tool based on Eclipse (a platform for application development, integrated development environment). With these additions it is possible to manage the entire lifecycle of all programming elements (resources) (SAP HANA views, SQLScript procedures, roles, HTML and JavaScript content, etc.).
SAP HANA Studio has been extended with new elements called SAP HANA Development. Extras such as a project wizard, code autocompleting and syntax highlighting functionality, integrated debugger, etc. increase developers productivity.
SAP HANA Studio
While programming in this environment, developers can use standard features available on the Eclipse platform, such as teamwork. Project files are stored in the SAP HANA repository, together with all other resources. Team members can use the SAP HANA repository browser to check for existing projects and import them directly to local workspaces. Then, developers can work on local versions of the code, often in the same time. When the code is saved back to the SAP HANA repository, the tool detects any conflicts, and developers can on an ongoing basis merge code fragments directly in the repository.
The SAP HANA repository also supports active / inactive workspace objects. With this feature, developers can safely save their work on the server, without immediately overwriting the current version. The new version of the code will not be created until the developer activates the object repository.
SQLScript
As already mentioned, the basis for the optimization of applications transferred to SAP HANA is moving the largest possible number of operations to the database level. This objective is achieved by using the standard SQL query language. However, if you want to create business logic at the database level, you also need the semantics which exceeds the capabilities of SQL. For that purpose, SAP provides such an SQL extension, called SQLScript.
SQLScript is the basic language for creating stored procedures and functions in SAP HANA. With the extensions provided by SQLScript, developers can transfer more operations to the database level.
Typical SQL queries are very well suited for parallel processing due to their declarative character. The main weakness of SQL becomes obvious when the results of one query must be transferred as an input to the next query. In such a case, developers have two options: copy query results to the application server or write complex, nested SQL queries using sub-queries or many join conditions.
SQLScript resolves this issue by providing the possibility to transfer data from one SQL query to another one. With this feature, developers can write the similar code as in the case of using the application server, and declare variables and use intermediate query results. Additionally, SQLScript may often be connected with sub-queries and different table joins. With these features, developers receive a syntax that is less complicated and easier to read, while providing logic adapted to the database. At the same time, SQLScript avoids sending huge data copies to the application server, and uses the complex parallel processing in a database instead.
Compared to standard SQL, SQLScript has several advantages. As a result, the processing procedures can return multiple results, while the SQL query can return only one result set. Another advantage is the division of complex SQL queries into smaller pieces. This allows modular programming, re-use of functions, and better code clarity.
Additionally, the standard SQL syntax allows developers to only define SQL views; however, these views have neither parameters nor a fixed interface. Another advantage of SQLScript is the support for local variables without explicitly defined types. In standard SQL, visible global views must be defined, even if they are used only for storage of intermediate query results. Moreover, SQLScript has a control logic such as if / else, not available in standard SQL. And finally, SQLScript can increase overall performance by using parallel processing in majority of SQLScript code executions.
This document presents the most important aspects of working in the SAP HANA environment as a developer. Creating applications within SAP HANA is a very complex topic, but the scale of software development capabilities in this technology is enormous. The maximum application usability with the maximum use of the database infrastructure opens completely new prospects for the development of business solutions.